

โลกของข้อมูลกำลังเกิดการเปลี่ยนแปลงครั้งสำคัญ จากเดิมที่ข้อมูลส่วนใหญ่ถูกเก็บไว้ใน data center กำลังย้ายมาอยู่บนอุปกรณ์ปลายทาง (edge devices) รอบตัวเรา ไม่ว่าจะเป็นสมาร์ทโฟน เซ็นเซอร์ และอุปกรณ์ IoT การเปลี่ยนแปลงนี้เองที่ทำให้ตลาด edge computing ทั่วโลกเติบโตอย่างมหาศาล จากมูลค่า 1.596 หมื่นล้านดอลลาร์ในปี 2023 และคาดว่าจะทะยานสู่ 2.1676 แสนล้านดอลลาร์ในปี 2032 บทความนี้จะพาคุณไปทำความเข้าใจว่าอะไรคือแรงผลักดันเบื้องหลังเทรนด์นี้ และเราจะนำพลังของ Edge AI มาสร้างแอปพลิเคชันอัจฉริยะได้อย่างไร
ข้อดีของการประมวลผลข้อมูลที่ Edge
หากย้ายการประมวลผลข้อมูลมาไว้ที่อุปกรณ์ edge นั่นไม่ใช่แค่การเปลี่ยนที่เก็บข้อมูล แต่เป็นการพลิกโฉมฟังก์ชันการทำงานและวิธีจัดการข้อมูลแอปพลิเคชันไปอย่างสิ้นเชิง และนี่คือข้อได้เปรียบสำคัญที่คุณจะได้รับ
- ทำงานได้แม้ไม่มีอินเทอร์เน็ต: หัวใจสำคัญของแอปพลิเคชัน edge คือความเสถียรและความสามารถในการทำงานได้ด้วยตัวเอง โดยไม่ต้องพึ่งพาการเชื่อมต่ออินเทอร์เน็ต ด้วยคุณสมบัติที่พร้อมทำงานเสมอนี้เองที่ทำให้มันยืดหยุ่นและนำไปปรับใช้ได้ในสภาพแวดล้อมที่หลากหลาย ตั้งแต่โรงงานอุตสาหกรรมในพื้นที่ห่างไกลที่สัญญาณเครือข่ายไม่เสถียร ไปจนถึงระบบในรถยนต์หรืออุปกรณ์ส่วนตัวที่อินเทอร์เน็ตอาจขาดหายเป็นช่วงๆ
ความสามารถในการประมวลผลข้อมูลได้ที่ตัวอุปกรณ์โดยตรง ช่วยรับประกันว่าการทำงานจะต่อเนื่อง ไม่สะดุด ซึ่งจำเป็นอย่างยิ่งสำหรับแอปพลิเคชันที่มีความสำคัญสูง นับเป็นหัวใจสำคัญของแอปพลิเคชันที่ต้องทำงานต่อเนื่อง แม้ในสภาวะที่การเชื่อมต่ออินเทอร์เน็ตไม่เสถียร - ประหยัดต้นทุนการ query ข้อมูล: การนำโมเดลประมวลผลข้อมูลมาใส่ไว้ในแอปพลิเคชันโดยตรง และจัดการการค้นหาทั้งหมดที่ตัวอุปกรณ์ จะช่วยให้องค์กรลดต้นทุนการรับส่งข้อมูลได้อย่างมหาศาล
- ตอบสนองได้แบบเรียลไทม์: การฝังโมเดลประมวลผลไว้ในตัวแอปพลิเคชันช่วยลดระยะเวลาส่งข้อมูลไป-มาระหว่างการค้นหาได้อย่างมาก การประมวลผลบนอุปกรณ์ทำให้เกิดการตอบสนองที่แทบจะในทันที ช่วยให้ผู้ใช้ได้รับประสบการณ์ที่ดีขึ้นอย่างชัดเจน การตอบสนองที่รวดเร็วนี้คือหัวใจสำคัญสำหรับแอปพลิเคชันที่ต้องทำงานแบบเรียลไทม์ เช่น augmented eeality (AR), ยานยนต์ไร้คนขับ และระบบควบคุมในอุตสาหกรรม
- ปกป้องข้อมูลส่วนตัวไม่ให้รั่วไหล: edge computing มีจุดเด่นที่การรักษาความเป็นส่วนตัวของข้อมูล ซึ่งถูกพัฒนาคุณภาพขึ้นโดยหลักการออกแบบของมันเอง นั่นหมายความว่าข้อมูลส่วนบุคคลและข้อมูลละเอียดอ่อนต่างๆ ที่เก็บไว้บนอุปกรณ์ต้นทาง และไม่จำเป็นต้องส่งข้อมูลออกไปข้างนอกอีกต่อไป แต่ทำการจัดการข้อมูลที่ตัวอุปกรณ์โดยตรง วิธีนี้จะช่วยลดความเสี่ยงจากการรั่วไหลของข้อมูล, การเข้าถึงโดยไม่ได้รับอนุญาต หรือการละเมิดข้อบังคับด้านข้อมูลได้เป็นอย่างดี
ปลดล็อกความอัจฉริยะให้ Edge Computing
การค้นหาเชิงเวกเตอร์ (vector search)
ก่อนจะไปเจาะลึกว่า vector search คืออะไรและทำงานอย่างไร เรามาทำความรู้จักกับ ‘เวกเตอร์’ (vector) กัน พูดง่ายๆ เวกเตอร์ ก็คือจุดข้อมูลหนึ่งๆ ที่ประกอบด้วยหลายตัวแปร โดยจะแสดงผลออกมาในรูปแบบของชุดตัวเลข คล้ายกับการระบุตำแหน่งด้วยค่าพิกัด (coordinates) นั่นเอง
เพื่อให้เห็นภาพของเวกเตอร์ชัดขึ้น ลองนึกถึงสิ่งที่เราคุ้นเคยกันดีอย่าง โมเดลสี RGB ที่ใช้ในจอทีวีหรือจอคอมพิวเตอร์ของเรา โมเดลนี้มีพื้นฐานมาจากแม่สี 3 สี คือ แดง, เขียว , และน้ำเงิน โดยแต่ละสีจะถูกแทนค่าด้วยตัวเลขหนึ่งค่า และเมื่อเรานำค่าตัวเลขของทั้งสามสีนี้มาผสมกันในสัดส่วนที่แตกต่างกัน ก็จะทำให้เกิดเป็นเฉดสีอีกนับล้านสีสันปรากฏขึ้นบนหน้าจอของเรานั่นเอง
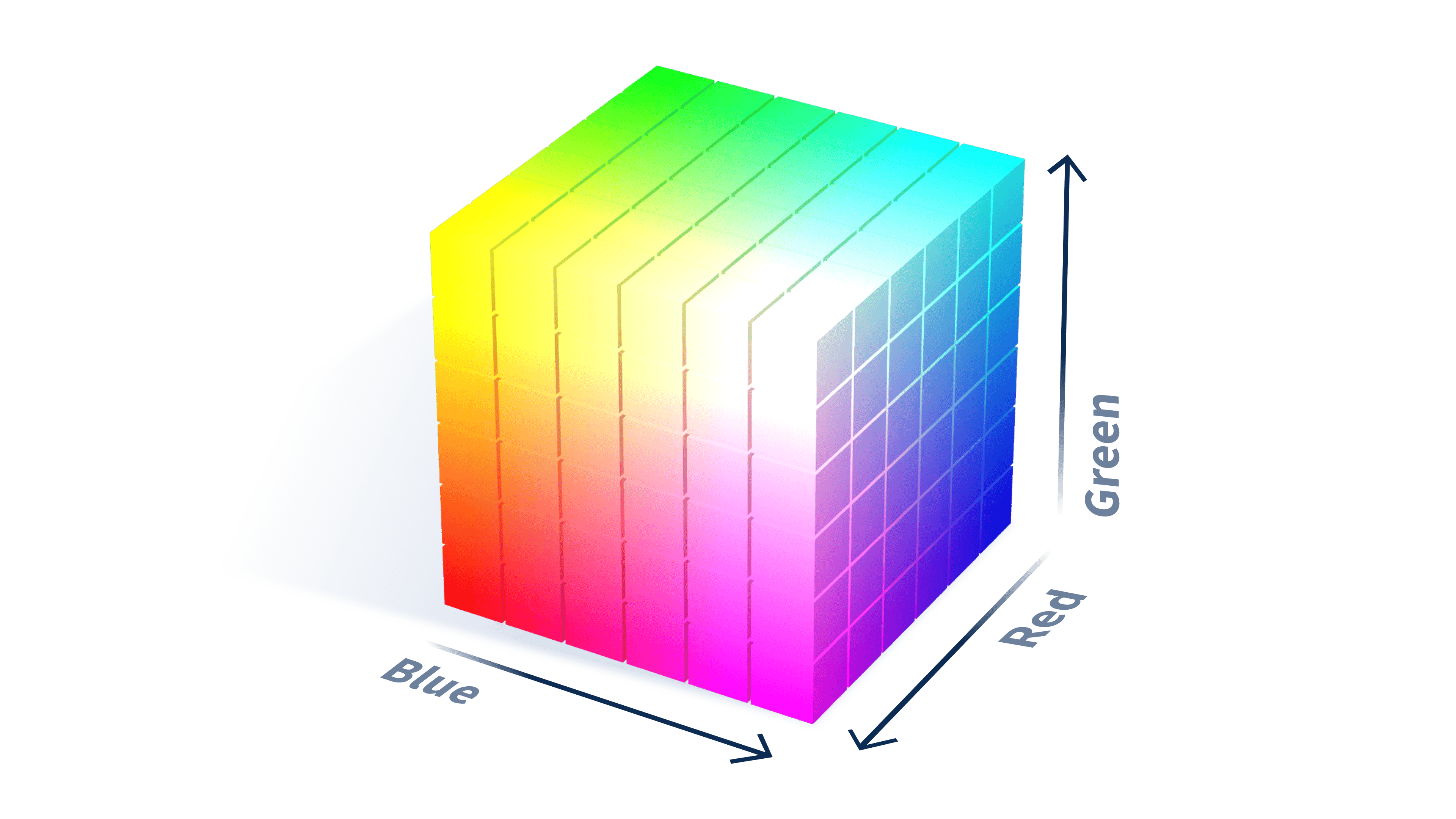
ภาพตัวอย่างโมเดลสี RGB จาก Mozilla
หลักการเดียวกันนี้คือหัวใจสำคัญที่ถูกนำมาปรับใช้ใน vector database โดย vector database ทำหน้าที่เป็นแหล่งจัดเก็บเวกเตอร์โดยเฉพาะ ช่วยให้ผู้ใช้สามารถค้นหาข้อมูลที่มีความหมายใกล้เคียงกันได้อย่างรวดเร็ว โดยจะแสดงผลการค้นหาที่รวดเร็วโดยอ้างอิงจากข้อมูลที่มีความคล้ายคลึงกันมากที่สุด ซึ่งแตกต่างจากฐานข้อมูลแบบเดิมที่อาจไม่ถนัดงานประเภทนี้ vector database จะเข้ามาช่วยให้เราสามารถจัดระเบียบ, ค้นหา และวิเคราะห์ข้อมูลที่ซับซ้อนได้อย่างมีประสิทธิภาพยิ่งขึ้น
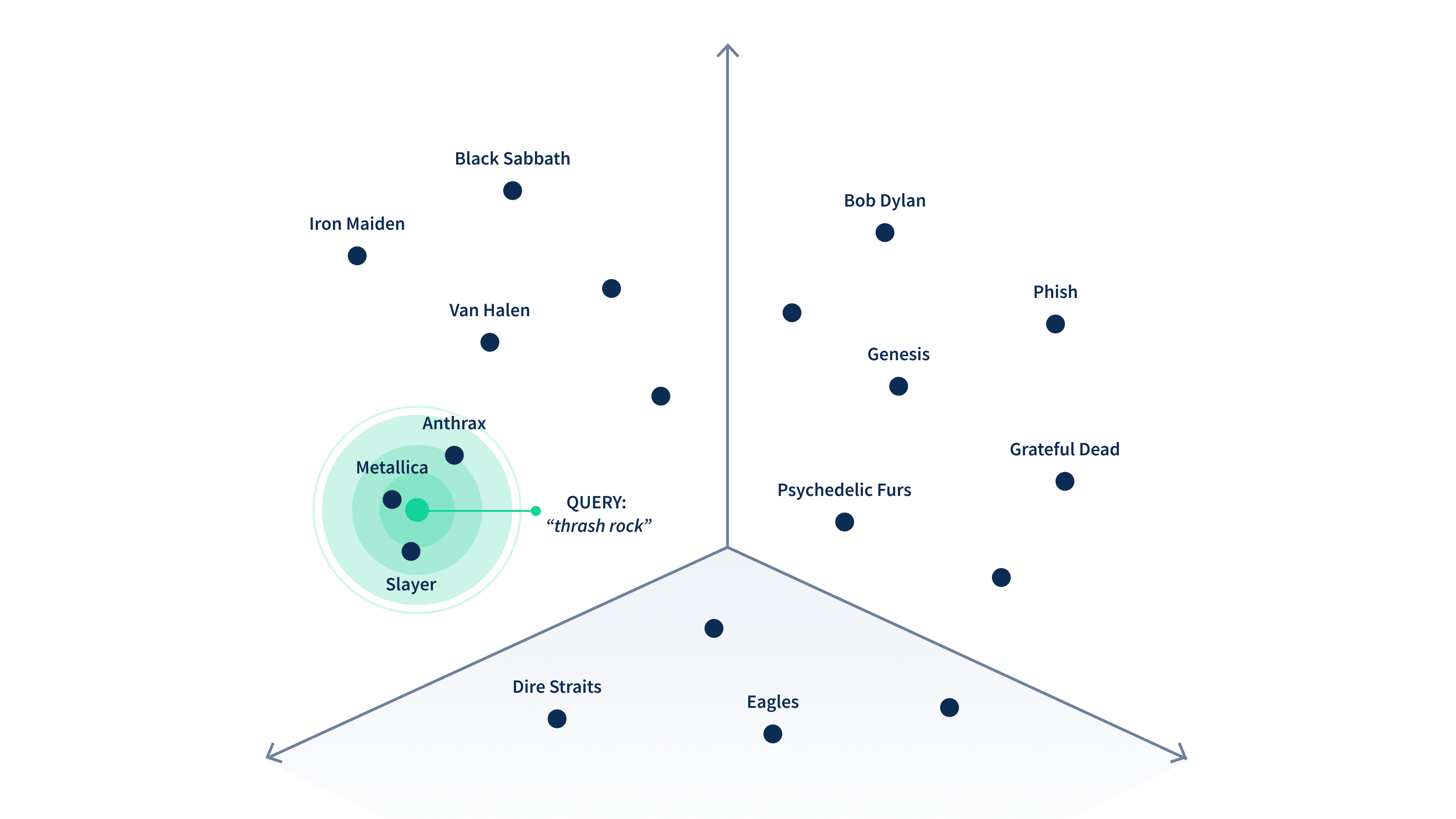
ภาพตัวอย่างการทำงานของ vector database จากCouchbase
แล้วเราจะระบุคุณลักษณะของเวกเตอร์แต่ละตัวในฐานข้อมูลได้อย่างไร? คำตอบก็คือ เราต้องใช้สิ่งที่เรียกว่า vector embeddings ลองจินตนาการว่ามันคือ ลายนิ้วมือดิจิทัล หรือ DNA ของข้อมูล ซึ่งเป็นชุดตัวเลขยาวๆ ที่ทำหน้าที่อธิบายคุณสมบัติเด่นๆ ของวัตถุชิ้นนั้น กระบวนการค้นหาวัตถุต่างๆ ที่มีคุณสมบัติใกล้เคียงกันใน vector database นี่เอง ที่เราเรียกว่า vector search
หัวใจสำคัญที่ทำให้ vector search ทรงพลังก็คือ มันทำให้เราค้นหาข้อมูลจาก "ความหมาย" ไม่ใช่แค่จาก "คำที่พิมพ์ตรงกัน" วิธีนี้ไม่เพียงแต่จะช่วยให้ผลการค้นหาตรงกับความต้องการของเรามากขึ้น แต่ยังช่วยลด AI hallucinations หรือการที่ AI สร้างข้อมูลที่ไม่มีอยู่จริงขึ้นมา ถือเป็นการยกระดับความน่าเชื่อถือของระบบสืบค้นข้อมูลโดยรวมให้มีคุณภาพขึ้นไปอีกขั้น
RAG: เมื่อ AI ไม่ได้ตอบจากความจำ แต่ค้นข้อมูลมาตอบ
RAG (Retrieval-augmented Generation) คือเทคนิคที่ช่วยเพิ่มข้อมูลบริบทหรือในที่นี่คือเวกเตอร์ เข้าไปใน LLM prompts เพื่อให้ AI สามารถสร้างคำตอบที่แม่นยำและตรงประเด็นมากยิ่งขึ้น หรือพูดง่ายๆ ก็คือ แทนที่ AI จะตอบจากสิ่งที่จำมาอย่างเดียว แต่มีการเปิดหนังสือหรือดึงข้อมูลที่เกี่ยวข้องที่สุดมาประกอบการตอบด้วย
เบื้องหลังการทำงานของมันเรียบง่ายแต่ทรงพลังมาก เริ่มต้นด้วยการสร้างและจัดเก็บลายนิ้วมือดิจิทัลของข้อมูล (vector embeddings) จากนั้นใช้ vector search เพื่อค้นหาข้อมูลที่มีความหมายใกล้เคียงกับคำถามของเราที่สุด สุดท้าย คือการส่งข้อมูลที่ค้นเจอ พร้อมกับคำถามตั้งต้นของเรา ไปให้โมเดล AI เพื่อสร้างคำตอบที่รู้ใจและเฉพาะเจาะจงสำหรับเรามากที่สุด
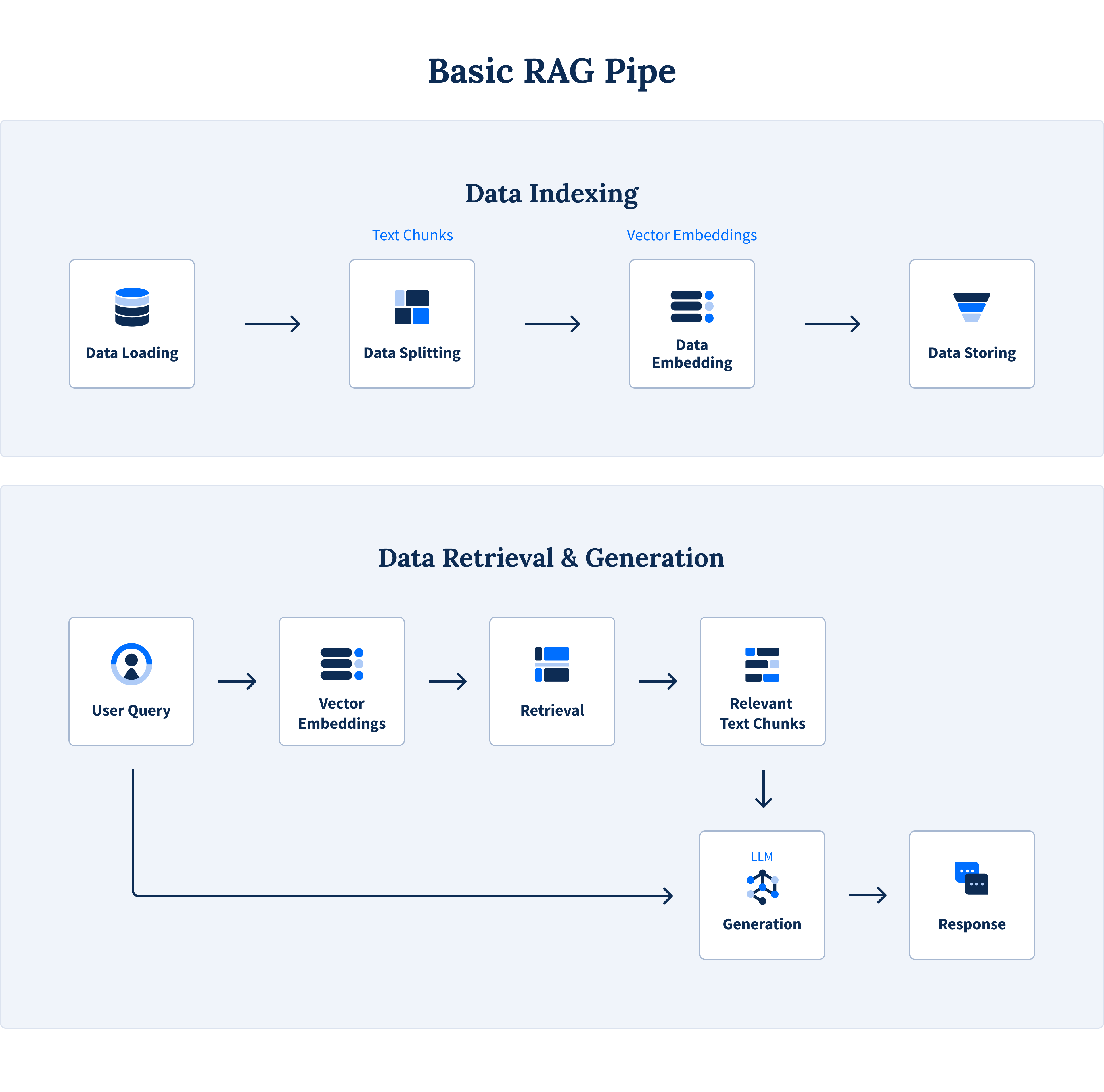
ภาพแสดงขั้นตอนการทำงานพื้นฐานของ RAG จาก Astera Software
การซิงค์ข้อมูลแบบ P2P: เชื่อมต่อกันโดยตรง ไม่ต้องง้ออินเทอร์เน็ต
ลองนึกภาพอุปกรณ์ต่างๆ ที่อยู่ในเครือข่าย Wi-Fi เดียวกัน สามารถส่งข้อมูลหากันได้โดยตรง โดยที่ไม่ต้องเชื่อมต่ออินเทอร์เน็ตหรือผ่านเซิร์ฟเวอร์กลางเลย นี่คือหัวใจของ P2P Sync (Peer-to-peer Sync) เทคโนโลยีนี้เข้ามาตอบโจทย์ในสถานการณ์ที่อินเทอร์เน็ตขาดหายหรือไม่เสถียร ลองนึกถึงทีมงานภาคสนามที่ทำงานในพื้นที่ห่างไกล หรือพนักงานร้านค้าที่ต้องการอัปเดตข้อมูลกันภายในสาขา พวกเขาสามารถแบ่งปันข้อมูลล่าสุดถึงกันได้อย่างราบรื่น โดยไม่ต้องกังวลเรื่องการเชื่อมต่อกับคลาวด์เลย
การนำ Edge AI มาใช้งานจริง
- ขับเคลื่อน LLM ด้วยเฟรมเวิร์กยุคใหม่ การจะทำให้โมเดลภาษาขนาดใหญ่ (LLM) อย่าง Gemma 2 สามารถทำงานบนอุปกรณ์ Android ได้นั้น เฟรมเวิร์กยุคใหม่อย่าง Google's MediaPipe คือหัวใจสำคัญ โดยทำงานผ่าน MediaPipe LLM inference API เครื่องมือเหล่านี้เปิดโอกาสให้นักพัฒนาสามารถย่อส่วนและปรับแต่งโมเดล AI ขนาดใหญ่ ให้ทำงานได้อย่างเต็มประสิทธิภาพบนฮาร์ดแวร์ของอุปกรณ์พกพา และในกรณีที่คุณต้องการใช้โมเดลอื่นนอกเหนือจากโมเดลพื้นฐานที่ Google AI Edge รองรับ คุณจะต้องใช้เครื่องมือแปลงเพื่อเปลี่ยนโมเดลนั้นให้อยู่ในรูปแบบที่ MediaPipe LLM inference API สามารถทำงานด้วยได้
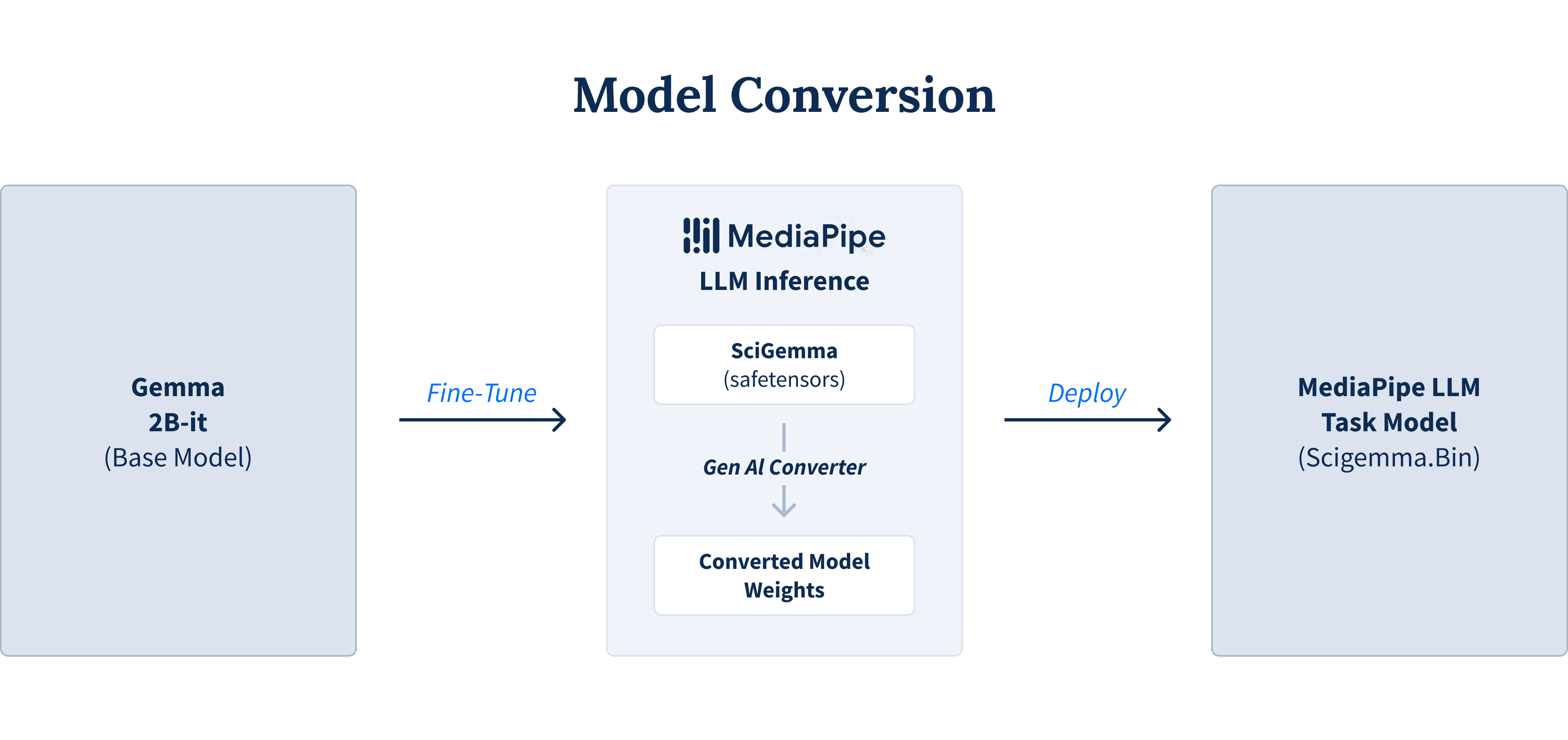
ภาพแสดงขั้นตอนการแปลงโมเดลสำหรับ MediaPipe จากบทความบน Medium โดย Google Developer Experts’ Medium
-
หัวใจสำคัญของการจัดการข้อมูลบนอุปกรณ์: เพื่อให้โมเดล AI เหล่านี้ทำงานได้อย่างเต็มศักยภาพ แอปพลิเคชันจำเป็นต้องมีระบบจัดการข้อมูลที่ไว้ใจได้ ซึ่งต้องรองรับทั้งโหมดออนไลน์และออฟไลน์, การซิงค์ข้อมูลตรงระหว่างอุปกรณ์ (P2P), และที่สำคัญคือการเข้ารหัสข้อมูลที่แข็งแกร่งบนตัวอุปกรณ์เอง
- สถาปัตยกรรมแบบไฮบริด: เชื่อมต่อทุกอย่างเข้าด้วยกัน ส่วนประกอบที่ทำงานบนอุปกรณ์นั้นเป็นจิ๊กซอว์ชิ้นสำคัญของสถาปัตยกรรมที่เชื่อมโยงทุกอย่างเข้าด้วยกัน ตั้งแต่ คลาวด์, edge servers ไปจนถึงอุปกรณ์ปลายทาง โดยการไหลของข้อมูลทั้งหมดในระบบนี้จะถูกดูแลและรักษาความปลอดภัยผ่านเกตเวย์
สร้างความได้เปรียบให้เหนือกว่าด้วย Edge AI
สำหรับธุรกิจที่มองหาความได้เปรียบในการแข่งขัน การนำ edge AI และ vector search มาใช้คือกุญแจสำคัญ เทคโนโลยีเหล่านี้คือหัวใจของการสร้างสรรค์แอปพลิเคชันอัจฉริยะยุคใหม่ ที่ไม่ได้มีแค่ความเร็ว ความปลอดภัย และความเป็นส่วนตัวสูง แต่ยังมาพร้อมความสามารถในการทำงานออฟไลน์ และฟีเจอร์ที่รู้ใจผู้ใช้ตามบริบทการใช้งานจริง
หากเชี่ยวชาญในแนวทาง edge-first จะช่วยให้บริษัทสามารถสร้างสรรค์โปรดักต์ที่ตอบสนองได้อย่างฉับไว ตอบโจทย์ความต้องการของผู้ใช้ยุคใหม่ และสร้างความได้เปรียบครั้งสำคัญในตลาดได้อย่างแน่นอน
Pulkit Midha
Developer Evangelist at Couchbase
Pulkit คือนักพัฒนาโมบายล์ผู้มีความเชี่ยวชาญด้านสถาปัตยกรรมแบบ Offline-First, การซิงโครไนซ์ข้อมูลแบบเรียลไทม์ และการสร้างสรรค์ประสบการณ์ใช้งานที่ชาญฉลาด เขาเป็นศิษย์เก่าจากโครงการ Google Summer of Code (GSoC) และเป็นผู้ชนะการแข่งขันแฮกกาธอน โดยมุ่งเน้นการสร้างแอปพลิเคชันครอสแพลตฟอร์มที่มีเสถียรภาพสูง และมีส่วนร่วมอย่างแข็งขันในคอมมูนิตี้โอเพนซอร์สและกลุ่มนักพัฒนาอยู่เสมอ



