
The generation of data is rapidly shifting towards edge devices, including smartphones, sensors, and various Internet of Things (IoT) devices. This trend contributes to a major growth in the global edge computing market, which is expected to surge from $15.96 billion in 2023 to an estimated $216.76 billion by 2032. We will look at the factors driving edge data processing and how we can implement edge AI on it to create smarter applications.
The Benefits of Processing Data on Edge Devices
Processing data on edge devices greatly transforms the functionality of applications and their approach to handling information. Here are some key advantages.
- Offline processing: Edge applications are inherently reliable, designed to function autonomously regardless of internet connectivity. This "always-on" capability makes them exceptionally versatile for deployment in diverse environments, from remote industrial sites with unreliable network access to in-vehicle systems or personal devices where internet availability can be intermittent. The ability to process data locally ensures uninterrupted operation, which is important for critical applications where constant connectivity cannot be guaranteed.
- Reduced cost per query: By putting the data processing model directly into the application and managing search queries locally, organizations can greatly reduce their data transfer costs.
- Low latency and quick responses: Embedding the processing model within an application significantly reduces round-trip time for search queries. On-device processing leads to near-instantaneous responses, improving the user experience. Low latency is necessary for real-time applications like augmented reality, autonomous vehicles, and industrial control systems.
- Enhanced data privacy: A significant advantage of edge computing is the inherent enhancement of data privacy. By keeping personal and sensitive information on the device where it originated, the need for external transmission is eliminated. Localized data handling greatly reduces the risk of data breaches, unauthorized access, or compliance violations, as the data never leaves the user's controlled environment.
Enabling Intelligence in Edge Computing
Vector search
Before we look closely at what vector search is and how it works, let’s talk about vectors first. A vector is a data point with multiple variables, represented as an array of numerical values, such as coordinates.
Take the RGB color model as an example use case of a vector. It’s commonly used in televisions and computer monitors. It’s based on three primary colors: red, green, and blue. Each color is represented by a value, and by combining these values in different ways, a broad spectrum of colors can be produced on screens.
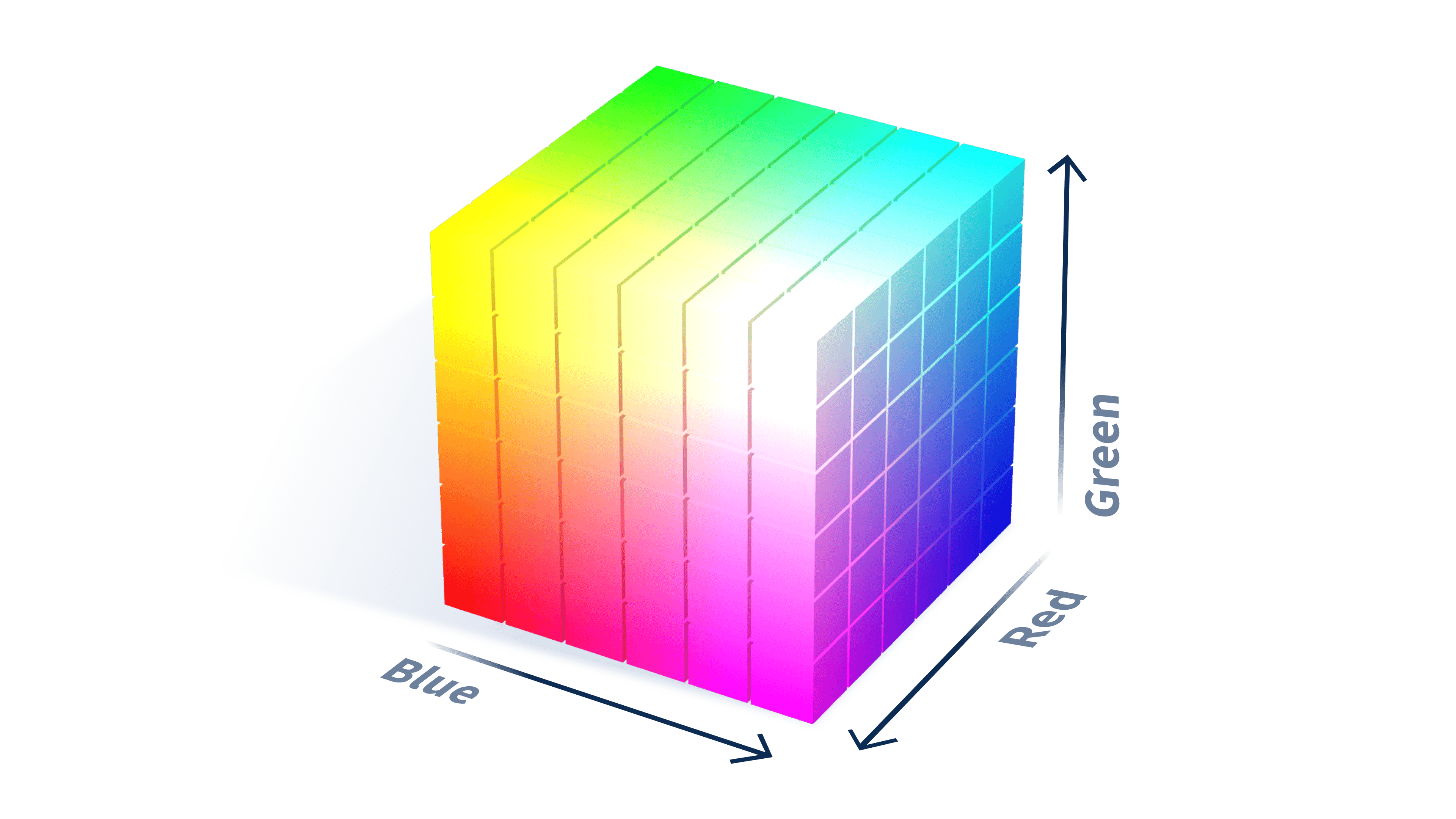
Example image of the RGB model from Mozilla
The same concept has been used in a vector database. A vector database is designed to store vectors and help users find and understand similar information quickly. It allows for fast search results based on the closest match. Unlike traditional databases, vector databases help organize, search, and analyze complex information more effectively.
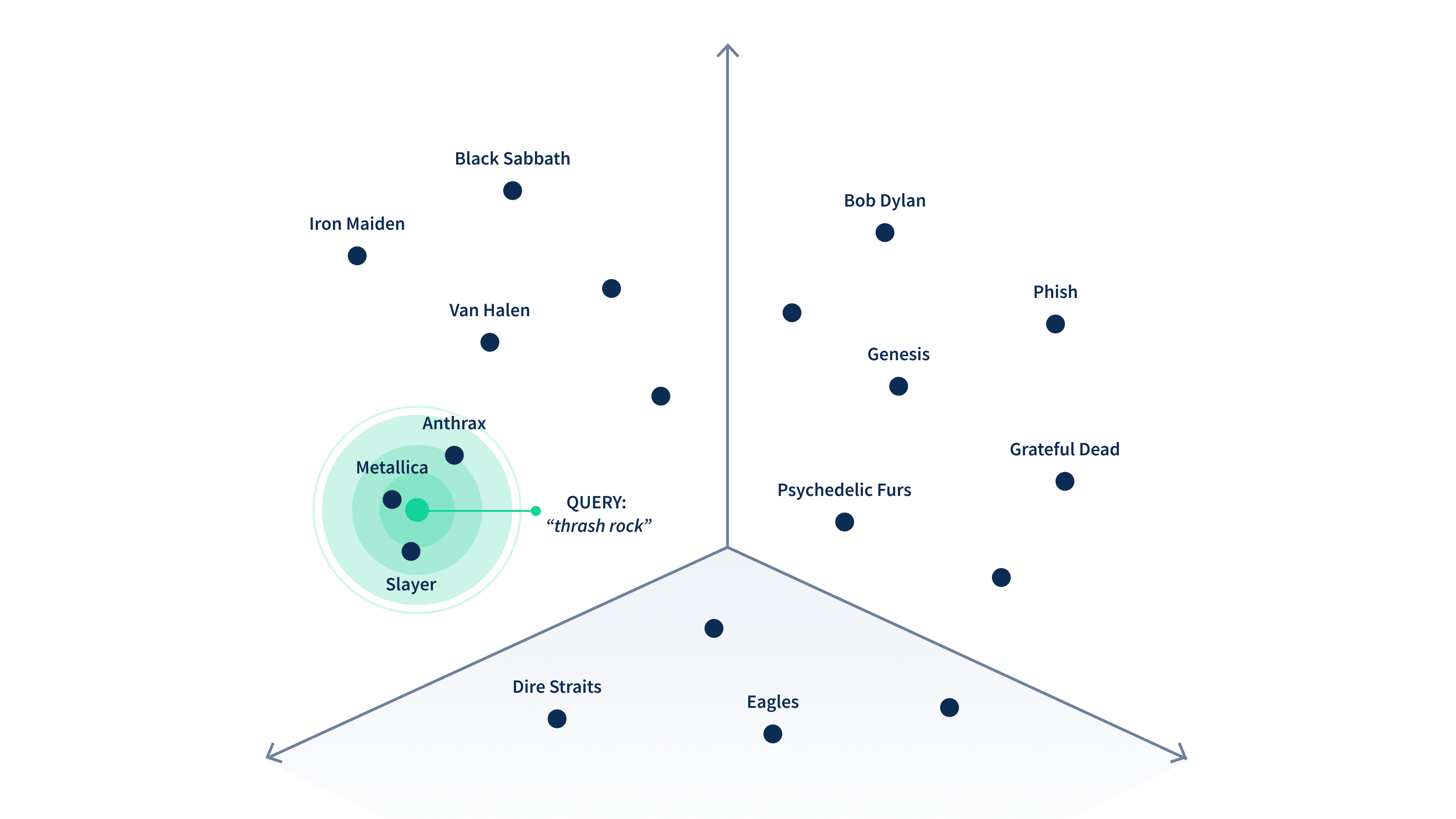
Example image of how the vector database works from Couchbase
To define the attributes of each vector or object in the database, you’ll need vector embeddings. They are a long list of numbers describing the features of an object.
The concept of searching objects that are close to each other in a vector database is called vector search. Vector search is important because it allows for searching based on the meaning of words, not just the words themselves. This approach not only enhances the relevance of search results but also helps minimize the occurrence of AI hallucinations, improving the overall reliability of information retrieval systems.
Retrieval-augmented generation (RAG)
RAG is a technique that adds contextual information (vectors) to LLM prompts to provide more accurate answers.
The process involves creating and storing vector embeddings, using vector search to find the nearest matches, and then sending those results along with the original query to an AI model to generate a hyper-personalized response.
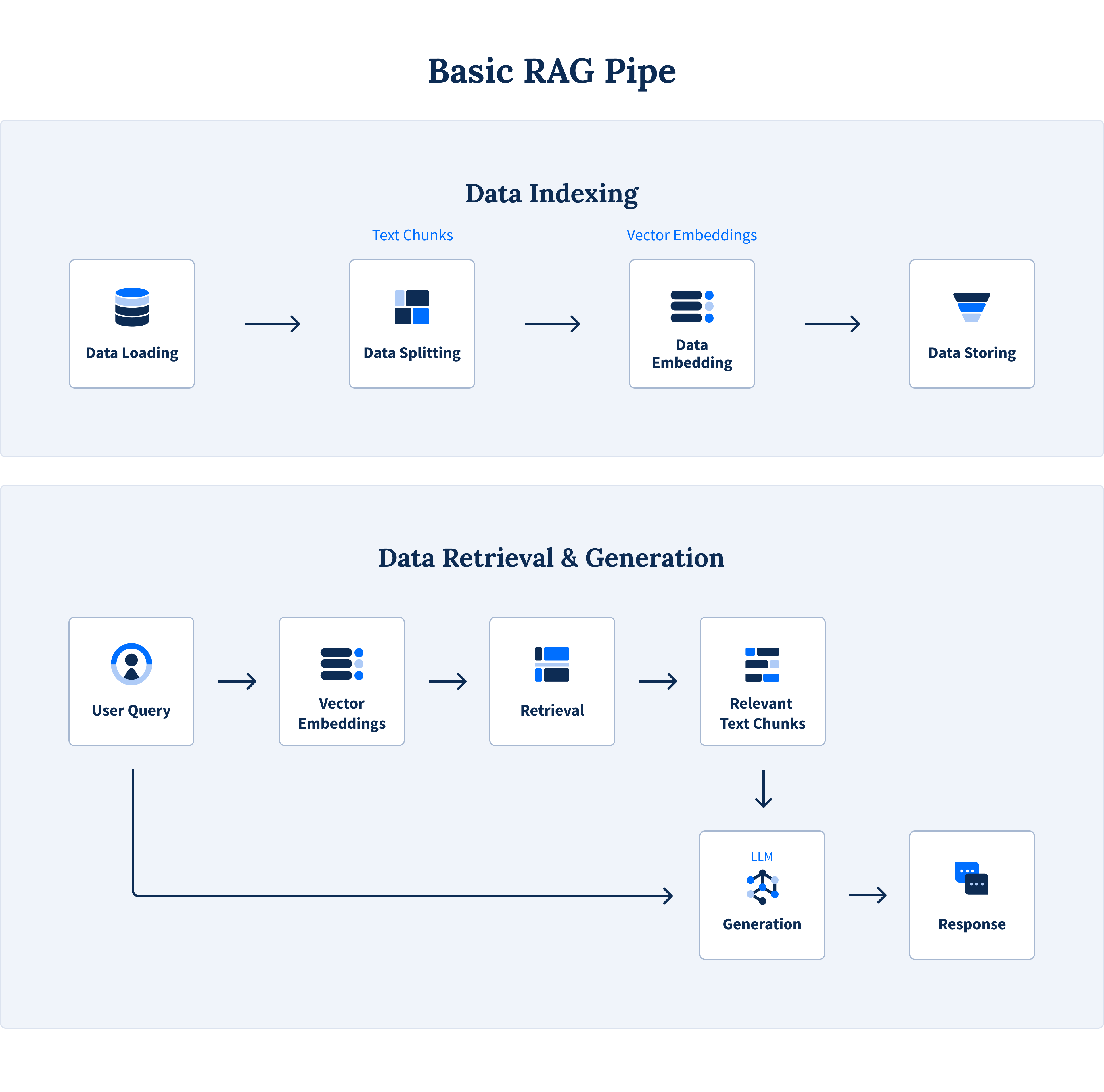
Image of a basic RAG pipeline from Astera Software
Peer-to-peer sync
P2P sync allows devices on the same local network (like Wi-Fi) to synchronize data directly with each other. No internet or central server needed. This is necessary in scenarios where internet connectivity is unavailable or unreliable. For example, a team of field workers in a remote location or retail employees within a single store can share updated information smoothly without connecting to the cloud.
Implementing Real-World Edge AI
- Enabling LLMs with modern frameworks: Frameworks like Google's MediaPipe are important for running LLMs like Gemma 2 on Android devices using MediaPipe LLM inference API. These tools allow developers to convert and optimize large AI models to run efficiently on mobile hardware. If you use a model outside of the default models supported by Google AI Edge, you have to use the converter.ConversionConfig method to convert the model into a format supported by MediPipe LLM inference API.
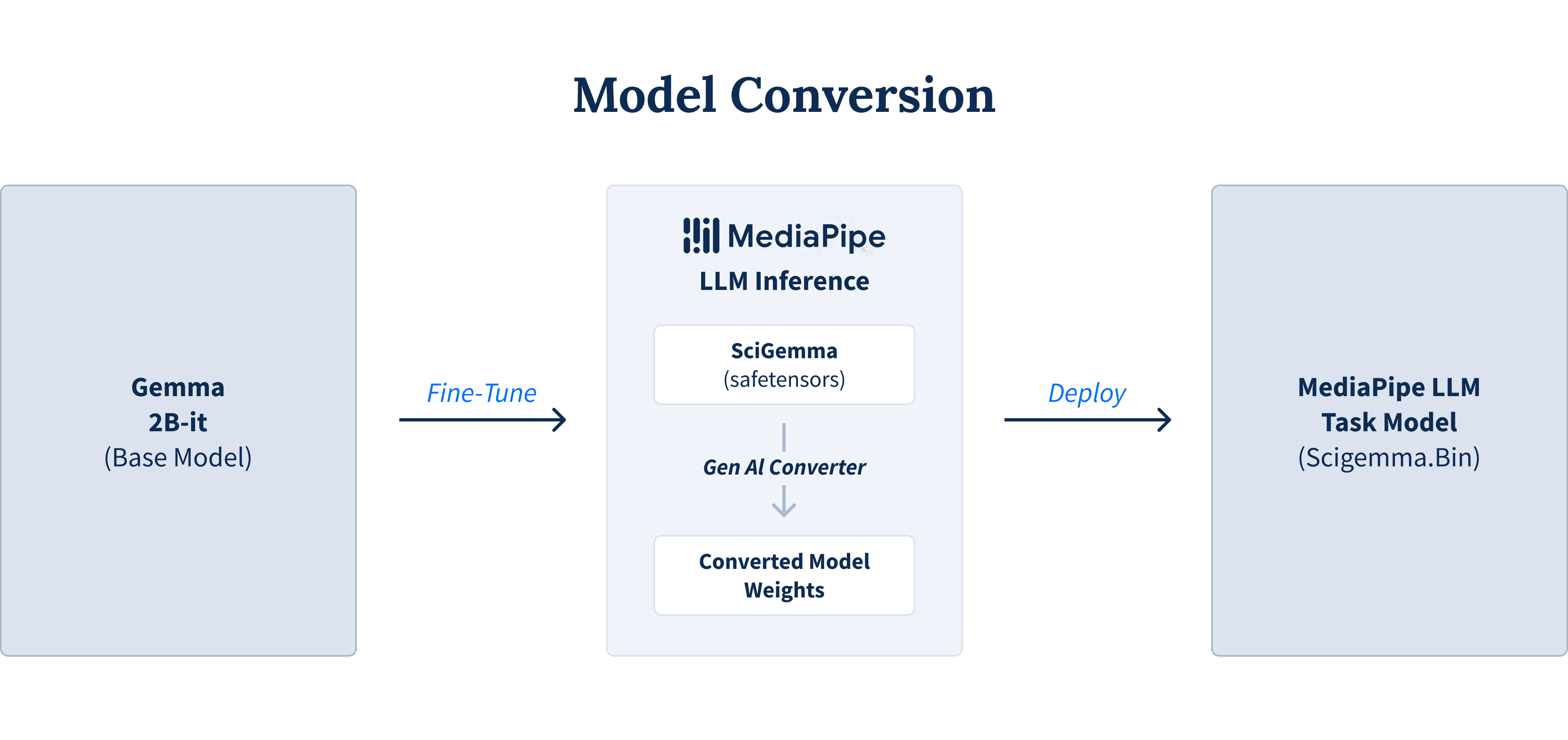
MediaPipe model conversion diagram from Google Developer Experts’ Medium
-
Core capabilities for on-device data:To support these AI models, applications need reliable data management features, including support for online and offline modes, peer-to-peer synchronization, and strong on-device encryption.
- Hybrid architecture: The on-device component is integral to a multi-tiered architecture, linking cloud, edge servers, and endpoint devices. Data flow is secured and managed by gateways across this entire system.
Your Competitive Edge at the Edge
For businesses seeking a competitive edge, adopting edge AI models and vector search is an important strategy. These technologies are central to building new generation of intelligent apps that are exceptionally fast, secure, and private, with offline capabilities and intuitive, context-aware features.
Mastering this edge-first approach allows companies to create highly responsive products that meet modern user demands and secure a major advantage in the market.
Pulkit Midha
Developer Evangelist at Couchbase
Pulkit is a mobile developer specializing in offline-first architecture, real-time synchronization, and intelligent client experiences. A GSoC alumnus and hackathon winner, he builds resilient cross-platform applications and actively contributes to open-source and developer communities.



