
Most organizations rushing to adopt AI overlook a critical reality: success depends on your data foundation, not your models. Companies invest heavily in sophisticated algorithms and cutting-edge models, only to discover their initiatives stall because the underlying data infrastructure can't support them.
The unglamorous truth is that building intelligent applications requires starting with a robust data infrastructure that turns raw information into a strategic asset.
Turning your Data Swamp into Something Useful
In practice, the situation resembles a "data swamp." Information is fragmented across scattered files, labeling is inconsistent, and there’s no clear ownership or governance. In this environment, even the most advanced AI models fail because they can't access reliable inputs.
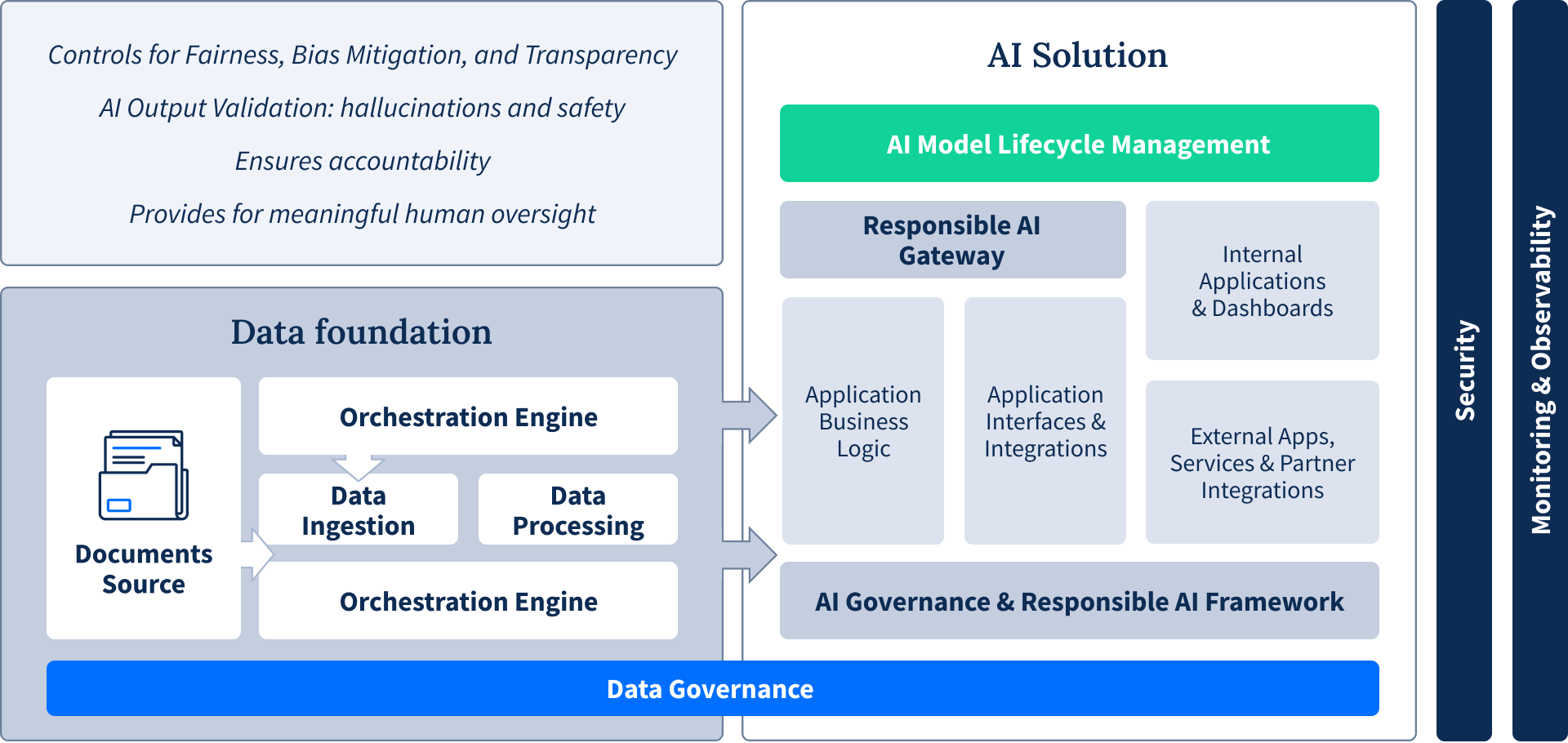
The solution lies in building a governed data foundation platform that consolidates fragmented information into a well-managed centralized system with a reliable single source of truth.
Designing for Governance and Compliance from Day One
For AI to be effective, the data it relies on must be trustworthy. Doing so requires considering governance and compliance from the start. Building trustworthy AI requires strict controls for fairness, bias mitigation, and transparency that ensure accountability and provide meaningful human oversight.
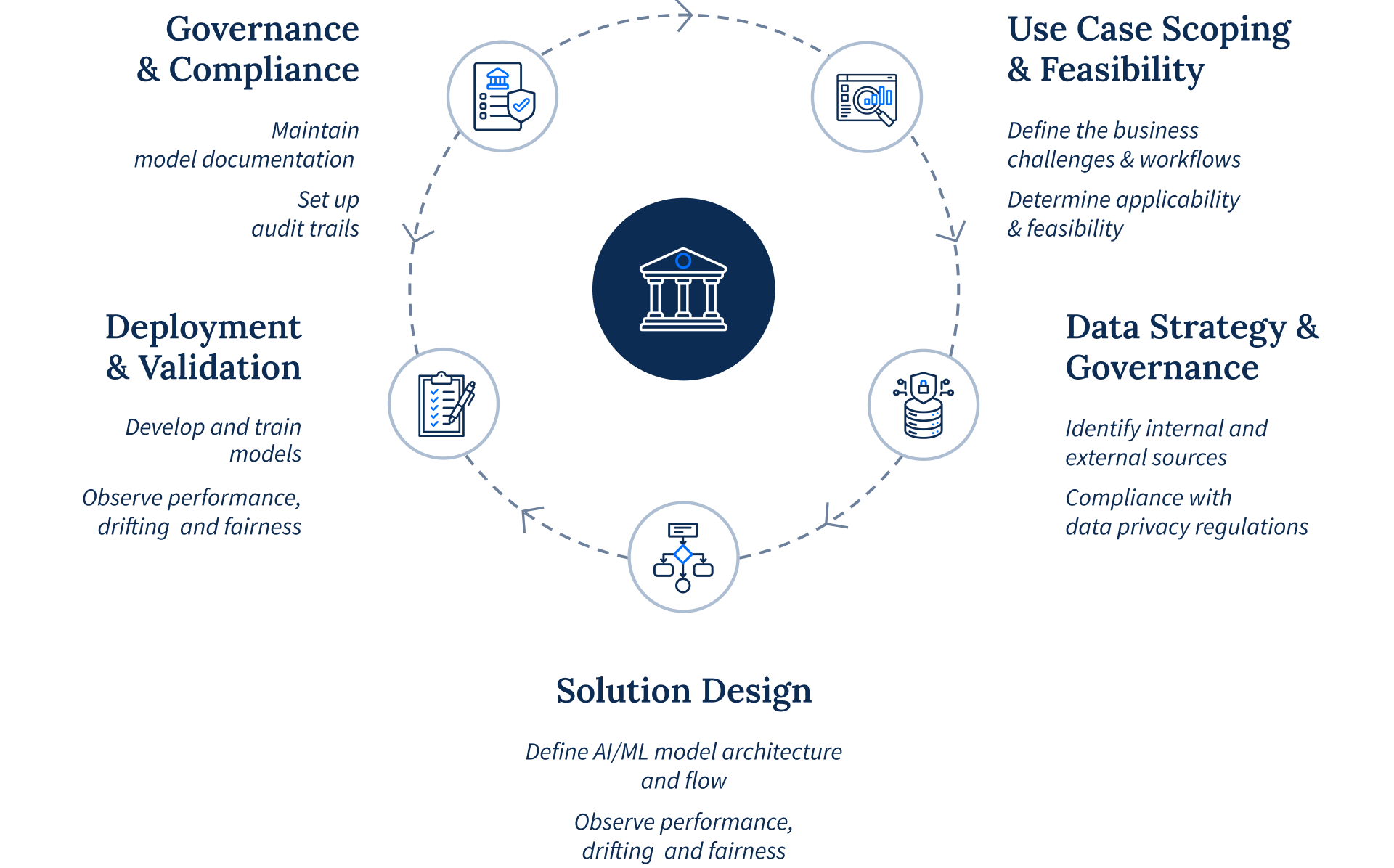
At the data foundation level, this means implementing role-based access controls, fine-grained lineage tracking, and automated masking of personally identifiable information (PII). These protections safeguard customer data, satisfy regulators, and prevent your models from leaking sensitive information.
Adherence to data privacy regulations like GDPR or PDPA is non-negotiable, and building these controls into your data ingestion pipeline from day one is far easier than retrofitting them later.
Matching Your Data Workflow to Your Needs
Before choosing an AI approach, it is important to consider your business goals and objectives. Start with the simplest solution that meets your needs, but architect your data foundation to scale toward more complex use cases as requirements evolve. Over-engineering from the start wastes resources, but under-building your data infrastructure creates costly technical debt.
The spectrum of AI complexity ranges from simple to sophisticated.
- LLM workflows can handle simple tasks like summarizing text or drafting emails based on straightforward prompts. Start here for basic text generation needs.
- RAG (Retrieval-Augmented Generation) grounds large language models in proprietary knowledge bases for accurate question answering. Choose this when you need AI to reference specific company information. Its effectiveness depends heavily on data quality.
- AI agents autonomously execute goal-based workflows like personalization or planning by interacting with well-defined tools. Consider agents when you need task automation with clear objectives.
- Agentic AI coordinates multiple agents to handle large-scale collaborative tasks autonomously. Reserve this complexity for workflows requiring extensive coordination across systems.
Match your initial implementation to your immediate business challenge, but ensure your data foundation can support the next level of complexity when needed.

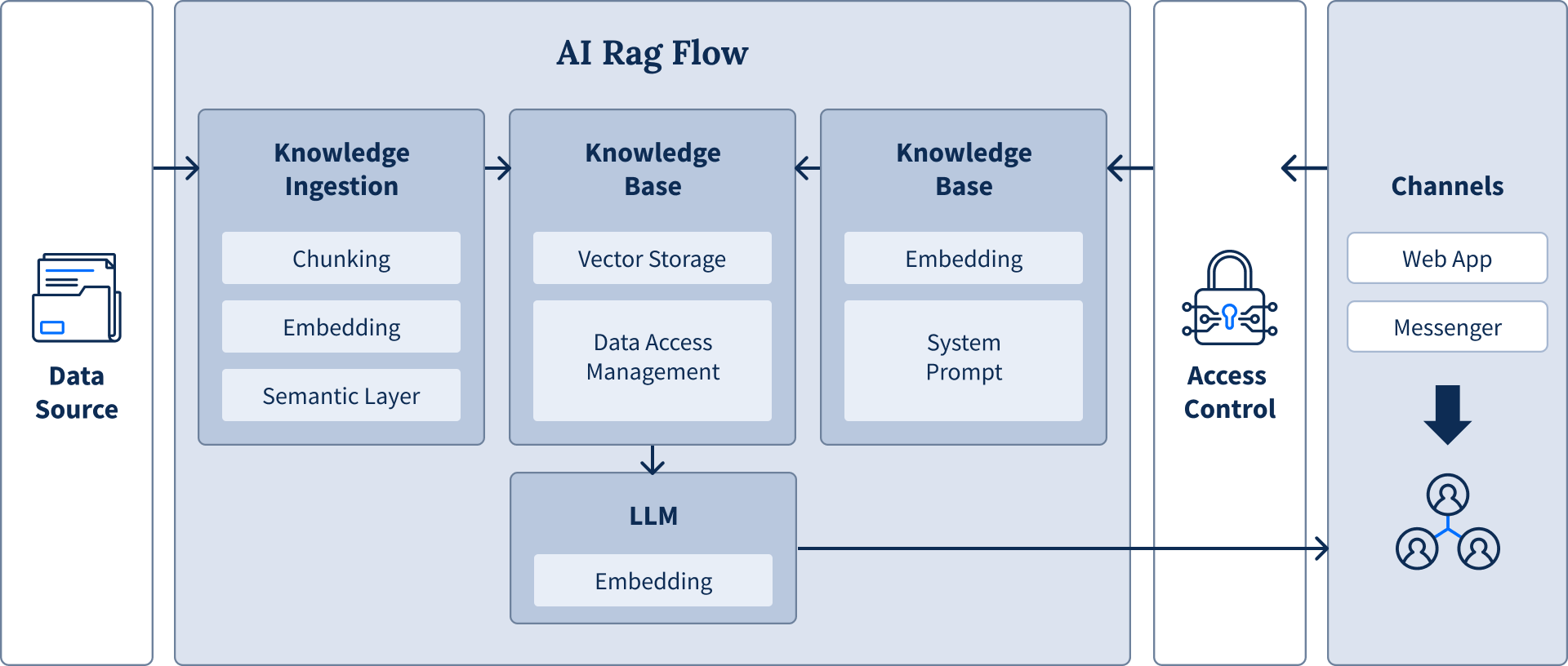
Preparing Your Data with RAG
Retrieval-Augmented Generation (RAG) bridges the gap between general-purpose language models and your proprietary knowledge. Instead of relying solely on what an LLM learned during training, RAG grounds responses in your specific data sources, enabling accurate answers about your products, policies, or internal knowledge base. This makes it essential for applications like AI-powered customer support, knowledge management systems, or business intelligence tools.
The RAG process transforms documents into semantically searchable information through a three-step pipeline. Documents are chunked into meaningful segments, converted into numerical vectors that capture their semantic meaning, and stored in specialized vector databases optimized for similarity searches. When users ask questions, the system retrieves the most relevant chunks to inform the LLM's response.
The three steps in this process are:
1. Chunking
Documents and data sources are broken into manageable pieces that AI can process efficiently.
2. Embedding
These chunks are converted into numerical representations that AI can understand and analyze.
3. Vector storage
The embeddings are stored in a searchable vector database, creating a powerful knowledge base the AI can draw upon instantly.
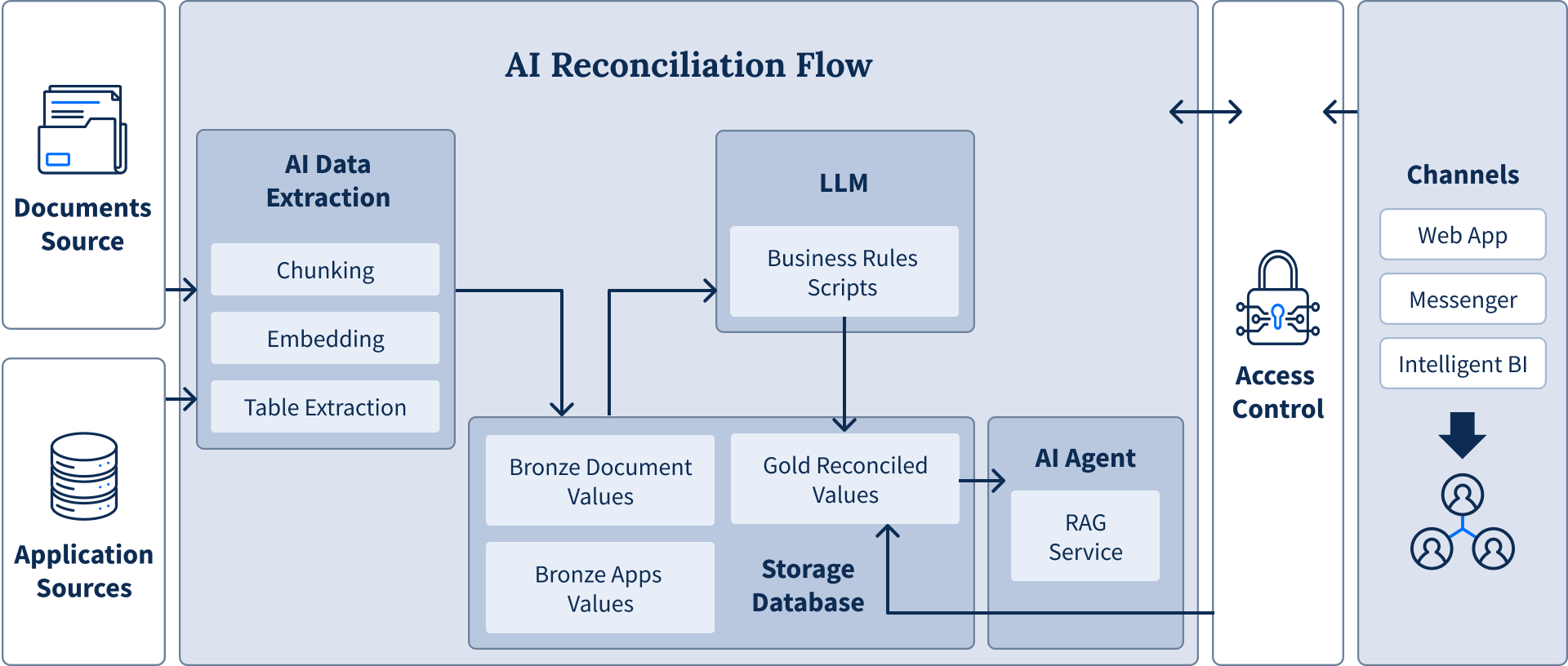
AI Ingestion in Action: Document Reconciliation
Document reconciliation demonstrates how AI data ingestion transforms business processes. The workflow begins with AI extracting data from documents through chunking and embedding, then structuring unstructured information into tables. This extracted data flows into a reconciliation engine that applies predefined business rules to compare information across multiple sources.
The system uses a medallion architecture (a layered approach that progressively refines data quality from raw inputs to validated outputs) to aggregate data from various sources and define clear data integrity workflows across systems. An AI agent orchestrates the entire process, handling notifications, corrections, and generating intelligent business intelligence reports. What once took days of manual work now completes in minutes, enabling real-time risk analysis and dramatically improved efficiency.
Your Blueprint for AI Success Starts with Data
AI success comes from architecting the entire ecosystem, starting with a strong, well-governed data foundation. Without such a foundation, you can't build intelligent applications that are reliable, compliant, and capable of delivering real business value.
Ready to transform your data foundation for AI? Our AI services and data analytics expertise help you build the governed data infrastructure that powers trustworthy, high-impact intelligent applications.
Damien Velly
VP of Data and AI at Seven Peaks
Damien brings over two decades of experience in the data and analytics field. He now leads the company's strategy, capabilities, and solutions for Data and AI.
.jpg?width=1756&height=1756&name=2023_Head%20of%20Data_Damien%20Velly_02%20(1).jpg)


